Team:Kyoto/Software
Software
Introduction
We are working on detecting virus damage in flower production in this project. Specifically, throughout our project, we have been trying to build a virus detection cycle (called DLA) in plant leaves. To this end, we made a virus detection device using RT-LAMP and fluorescence assay, combined with newly designed hardware.
The prior probability (*) is an important factor for such a device. Because image diagnosis is a promising tool to increase the prior probability, here we tried to implement image diagnosis of plant leaves. Since we could not collect a sufficient number of photos of an actual dahlia leaf infected by viruses, we used cherry leaves from a public database to train and evaluate our image diagnosis system. The results presented below show that in some cases, image diagnosis assisted with machine learning can detect infected leaves with higher accuracy than expected. We expect that our system should work equally well in different situations, such as viral infection of dahlias. To this goal, however, we need to obtain a wider range of data in order to evolve the software to contribute to the actual flower industry.

Fig.1 Plant Image Diagnostic Software
(*)What is Prior probability?

Fig2. Prior probability
Prior Probability is the likelihood of a positive or negative result before the test. In this case, it is the prevalence of a leaf before the RT-LAMP test results are available. The higher the prior probability of a positive result is, the higher the probability that the leaf is indeed diseased (positive predictive value) will be if the test result is positive. This is because the following equation is true for the positive predictive value(It is called Bayes theorem[1]).

Fig3. Bayes theorem
Increasing the prior probability of a positive result means increasing P(Bi), so if we increase the prior probability, the positive predictive value will also increase. This is strong evidence to support the RT-LAMP result. Similarly, if the prior probability of a negative result is increased, the negative predictive value will increase, which also supports the results of RT-LAMP.
And it is important not only to increase the prior probability of RT-LAMP test, but also to support the analysis of the results obtained by the test. For this purpose, we have developed a software that extracts the brightness of the samples in each well from the images of the test results taken with a smartphone.

Fig4. Brightness extraction software
By using this software to analyze the test results, it will become easier to determine whether each sample is positive or not. In addition, the results obtained using this software can be combined with leaf image data to create a new data set. With it, imaging AI can be evolved to be more adaptable to a wider range of data.
From the above discussion, it can be said that the above two software will greatly help and develop synthetic biology experiments as a part of DLA. We have named the former "DLAEMON" (diseased leaves assessment by efficient machine learning on neural network) and the latter "NOBITA" (numericalization of brightness of image for one touch assessment).
DLAEMON

about image diagnosis
There are several precedents for AI that can determine the type of disease from plant images. For example, an app called "garden doctor AI" can diagnose the type of disease on a plant or the type of insect that has eaten its leaves[2]. There is also an attempt to create an AI that can determine the type of disease from images of stems[3].
Plant image diagnosis using AI is currently being actively researched and used.
way of learning
To build this AI, we used a machine learning technique called deep learning. Among them, we used a method called fine-tuning.
What is machine learning and deep learning?
In order to build AI, a technique called machine learning is often used. In a nutshell, machine learning is the act of "deriving an algorithm that can perform a certain task with a certain level of performance through experience". Let me explain this with a simple example. AI is the core that executes the algorithm. For example, let's say you want to build an AI that can predict how much a house can be sold for based on two pieces of information: the number of rooms and the size of the lot. In this case, the "experience" is to see a large amount of data --number of rooms, the size of the lot--about the house whose selling price is already known. The "task" is to predict the selling price of the house, and the "performance" is the margin of error between the actual selling price of the house and the predicted price.
The "algorithm" is represented by a mathematical formula. In this example, let's say that a*(number of rooms)+b*(lot size)=(selling price). At this point, the values of a and b are determined through experience, and the final formula derived is the "algorithm". When predicting the selling price for unknown data, an AI implemented with this algorithm will output the predicted value by substituting the number of rooms and the size of the lot into the equation where a and b have been determined.
The "algorithm" is represented by a mathematical formula. In this example, let's say that a*(number of rooms)+b*(lot size)=(selling price). At this point, the values of a and b are determined through experience, and the final formula derived is the "algorithm". When predicting the selling price for unknown data, an AI implemented with this algorithm will output the predicted value by substituting the number of rooms and the size of the lot into the equation where a and b have been determined.
This is a very useful method. However, there is no proof that the selling price of a house depends only on the number of rooms and the size of the lot (the factors that form the basis for outputting the predicted value are called features). And we don't even know if this is really the best form of the "algorithm" equation. Maybe the selling price of a house is strongly correlated with the age of the house, or maybe the formula of the "algorithm" is more appropriate as a linear combination of the square of the number of rooms and the size of the lot. It is possible for humans to predict this to some extent, but there are limits.
This is where deep learning comes in. In deep learning, an "algorithm" is trained on a complex network of many nodes connected by many lines. Specifically, it is the process of storing a and b, in the previous example, into a large number of lines. This network is called a neural network. With deep learning, neither the features nor the form of the "algorithm" equation need to be determined by a human (I will explain the detailed learning process soon).
Before we discuss neural network learning methods, let's talk about the perceptron. The perceptron is the smallest unit that makes up a neural network and has the following structure.
This is where deep learning comes in. In deep learning, an "algorithm" is trained on a complex network of many nodes connected by many lines. Specifically, it is the process of storing a and b, in the previous example, into a large number of lines. This network is called a neural network. With deep learning, neither the features nor the form of the "algorithm" equation need to be determined by a human (I will explain the detailed learning process soon).
Before we discuss neural network learning methods, let's talk about the perceptron. The perceptron is the smallest unit that makes up a neural network and has the following structure.

Fig.5 perception
As shown in the figure above, enter a numerical value for the leftmost node. Each line has a "weight", which corresponds to a and b in the previous example. The entered values are multiplied by the weights and summed up as shown in the figure (the weights are called parameters). This is the input to the right node. At the right node, the input is assigned to the variables of a predetermined function, which becomes the output of the perceptron. This function is called the activation function.
A neural network is a combination of many perceptrons as shown to the right.

Fig.6 Neural network
Of course, every line has its own parameters. We input data to the leftmost nodes, and the values coming out of the rightmost layer are the predictions made by the AI. Incidentally, in our image recognition, the input data is the pixel data of the image converted into a vector. The output is a vector with the same number of elements as the class we want to classify (2 in this case). We decide in advance what class is represented by which number in this vector. The class corresponding to the largest element in the output vector will be the prediction of the neural network.
The parameters are initially set randomly, and deep learning updates them through a lot of input data to get the expected "algorithm" in the end.
So, how is the update done? To put it simply, we take the error between the value output by the current neural network and the value we want to output for a certain data, find out which parameter is responsible for the error and update each parameter so that the error becomes smaller. The function for defining the error is called the loss function, and this kind of update is called back propagation. The value that determines how much to update at a time is called learning rate.
There are several types of loss functions, and in this article we will introduce CrossEntropyLoss, which is represented by the following equation.

Fig.7 Cross Entropy
In this case, k is 2 because it is a two-class classification. The class representing a healthy leaf is 0, and the class representing a disease is 1. For example, when the data of a healthy leaf is input, t_0=1, t_1=0. The goal is to train the parameters to output as large y_0 value as possible when the input data is healthy leaves, and as large y_1 value as possible when the input data is sick.
There are several ways to update the parameters (called optimization algorithm), but here we will introduce the SGD algorithm, which can be expressed as follows

Fig.8 SGD algorithm
This formula means that for each parameter, we update it in a direction that makes the error value as small as possible.
In deep learning, the parameters are updated over and over again. In order to do this, we need a large amount of data that we already know has the correct output. The data used to update the parameters is called training data.
Even if we are able to achieve good performance on the training data, it is not enough.At this point, the neural network may overfit the training data and may not perform well on other data (this is called over-fitting). Therefore, it is necessary to evaluate the performance of the neural network using data that is different from the training data and is not used for updating parameters. The data for performance evaluation can be divided into two main types: validation data and test data.
In deep learning, the parameters are updated over and over again. In order to do this, we need a large amount of data that we already know has the correct output. The data used to update the parameters is called training data.
Even if we are able to achieve good performance on the training data, it is not enough.At this point, the neural network may overfit the training data and may not perform well on other data (this is called over-fitting). Therefore, it is necessary to evaluate the performance of the neural network using data that is different from the training data and is not used for updating parameters. The data for performance evaluation can be divided into two main types: validation data and test data.
First is the validation data. This data is used to compare the performance of a neural network by changing factors that are not updated by learning (called hyperparameters), such as the number of layers of the neural network, the number of trials the entire training data should be trained (called the number of epochs), and the ratio of the learning rate should be. Using this validation data, we compare various neural networks, and the one with the best performance becomes the final network to be adopted. Second is the test data. it is used to see how well the adopted neural network performs in general. The reason for separating the validation data from the test data is that since the hyperparameters are determined using the validation data, the neural network is more likely to perform better than the general for the validation data.
Data used for training and evaluation were downloaded from the site called plantvillage[4]. In this case, we trained Cherry_(including_sour)Powdery Mildew as disease data and Cherry_(including_sour)healthy as healthy leaf data in the "color folder" in the dataset.. The number of training data is 1146, the number of validation data is 360 (healthy leaves:diseased leaves=5:5), and the number of test data is 400 (healthy leaves:diseased leaves=5:5). According to the lecture movie[5], if the total number of data is on the order of 1000 or so, it is customary to divide the train, val, and test sets at the ratio of roughly 6:2:2, so we divided the data by this ratio.
We performed fine tuning using pre-trained ResNet18. The loss function is CrossEntropyLoss, the optimization algorithm is SGD, and the number of epochs is 20. The learning rate was set to 1.0*10^-4 for the diverted layer and 1.0*10^-3 for the newly replaced final layer. (see the code for details). ResNet18 is a convolutional neural network (CNN, a network that has improved its learning efficiency by performing what are called convolution and pooling on input data) with a depth of 18 layers. A pre-trained ResNet18, trained on over a million images, can be loaded from the ImageNet database. This pre-trained network can classify images into 1000 classes (animals, pencils, etc.). The paper that proposed ResNet can be found here[6].The learning rate was determined by comparison of validation data.
Data used for training and evaluation were downloaded from the site called plantvillage[4]. In this case, we trained Cherry_(including_sour)Powdery Mildew as disease data and Cherry_(including_sour)healthy as healthy leaf data in the "color folder" in the dataset.. The number of training data is 1146, the number of validation data is 360 (healthy leaves:diseased leaves=5:5), and the number of test data is 400 (healthy leaves:diseased leaves=5:5). According to the lecture movie[5], if the total number of data is on the order of 1000 or so, it is customary to divide the train, val, and test sets at the ratio of roughly 6:2:2, so we divided the data by this ratio.
We performed fine tuning using pre-trained ResNet18. The loss function is CrossEntropyLoss, the optimization algorithm is SGD, and the number of epochs is 20. The learning rate was set to 1.0*10^-4 for the diverted layer and 1.0*10^-3 for the newly replaced final layer. (see the code for details). ResNet18 is a convolutional neural network (CNN, a network that has improved its learning efficiency by performing what are called convolution and pooling on input data) with a depth of 18 layers. A pre-trained ResNet18, trained on over a million images, can be loaded from the ImageNet database. This pre-trained network can classify images into 1000 classes (animals, pencils, etc.). The paper that proposed ResNet can be found here[6].The learning rate was determined by comparison of validation data.

Fig.9 Illustration of fine tuning
Fine tuning is a technique that uses a large neural network with parameters pre-trained on different data, replaces the last layer with several new linear layers, and then trains each layer with your own data at different learning rates. In this case, we used ResNet18.
result of learning
The learning curve is as follows: the final accuracy for the training set is 99.9%, the final accuracy for the val set is 99.7%, and the accuracy for the test set is 99.8%.

Fig.10 Obtained learning curve
user interface
All you have to do is upload a photo of the cherry blossom leaf taken with your smartphone and click the diagnose button. However, please make sure that the photo shows only one leaf and has plain background. Only png, jpg, and jpeg styles are available. In addition, make sure that your image is RGB style, not CMYK or RGBA.
Step 1. When you launch the app, you will see this screen. Click the button "Choose image" to upload the image you want to diagnose.

Step 2.Then choose your image and upload it.

Step 3. When you see that the image you chose can be previewed, click the "Diagnose" button.

Step 4.You will see the result (in this case HEALTHY) and probability that the diagnosis is correct above the image.

Step 5.If you want to diagnose another image next, click "Upload Image" button under the image and go back to Step2.
The following image is an INFECTED one.
The following image is an INFECTED one.

There are only two buttons on the screen of this software: the upload button and the diagnosis button. This simple structure encourages the user to intuitively understand how to use the software.
great points of this software
- As mentioned at the first part of this article, by using this software for diagnostic imaging, the prior probability of being positive/negative before performing the RT-LAMP test is greatly increased. This corroborates the results of RT-LAMP. In addition, images that are not included in the training data, or leaves that were not distinguishable by the human eye in the first place, can be added to the dataset with the images and the results of the RT-LAMP test. By increasing the number of datasets in this way, the possibility of creating AI that can adapt to a wider distribution of data increases.
- Disease detection is of great interest to many iGEM teams(For example Team: UiOslo Norway-iGEM 2018[7], Team:USP-Brazil-iGEM 2017[8]). AI-based detection will surely become a cornerstone for future iGEM teams.
- No special machine is needed to take the photos. You can directly diagnose the photos you take using your own smartphone. This saves costs and human effort.
- The AI we have built is highly versatile. The learning method used in this study is called fine tuning. If we use the AI we have built this time and perform fine tuning in the same way, it will be easy to build diagnostic imaging AI for other plants. In order to confirm the usefulness of fine tuning, we built an image diagnosis AI of cherry blossom leaves using CNN from the beginning and compared it with the one trained by fine tuning. Two learning curves are shown below. The upper one is the case using fine tuning, and the lower one is the case using our own data and trained with CNN from the beginning. When training CNN from scratch, we used the same training set, validation set, and test set that we used for fine tuning. The CNN has a structure of convolution, max pooling, batch normalization, and dropout repeated twice(check the code for details). As you can see from these two curves, the one with fine tuning reaches higher accuracy faster than the one without it. As you can see, the strength of fine tuning is that it allows us to build an AI with high accuracy even with a small amount of data and a short training time. It is also easy to construct image diagnosis AI for other plants such as dahlia by using the AI constructed in this study and further fine tuning.Given this difference using ResNet18, a network trained on data that is not the images of healthy/diseased leaves of plants, we expect that fine-tuning with the AI we have built will yield more accurate results. The following are some papers about fine-tuning[9][10].
fine tuning :
CNN from scratch :

NOBITA
With this software, you can upload an image of the RT-LAMP results taken with your smartphone, and output the brightness of the location by simply clicking on the sample.
great points of this software
- You don't need any special machine to take pictures. You can use the same photos you take with your smartphone. This helps to reduce costs and human effort.
- This software allows the user to freely specify which part of the image to extract the luminance from. Therefore, this software can be used to diagnose not only the results of RT_LAMP test, but also the images of various fluorescence expressions.
- With this software, you can distinguish between luminances that are too similar to be distinguishable with the naked eye with accurate values.
user interface
As with DLAEMON, there is only a "Choose image" button and a "Display brightness" button on the screen. It is very intuitive and easy to understand. Just click on the location you are interested in, and you can easily display the brightness of that location. To be more specific, please follow the steps below.
Step 1. When you start the software, the following screen will appear.

Step 2. Press "Choose image" button and choose your image.

Step 3. The image will be automatically processed and displayed as a square black and white image.

Step 4. Click on the location where you want to extract the brightness. The number will be assigned in the order you clicked.

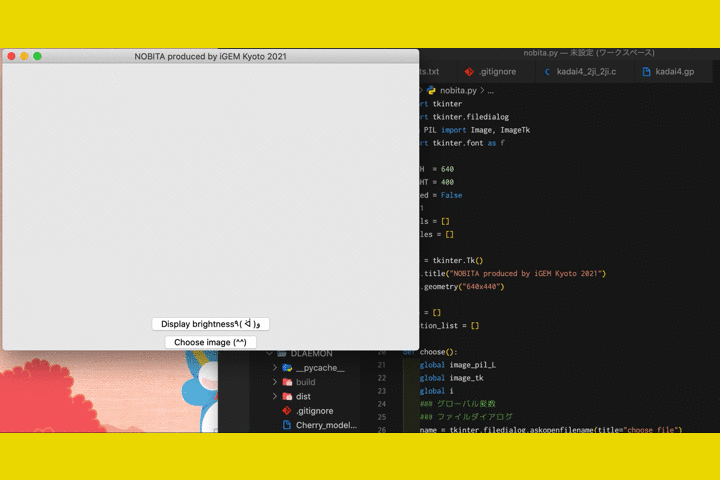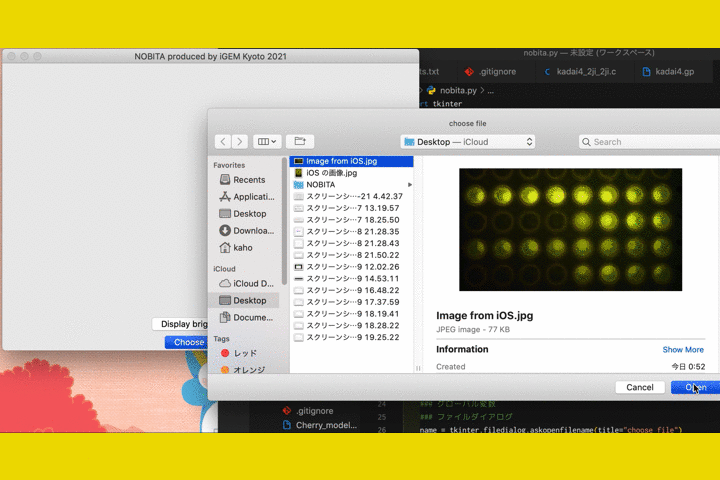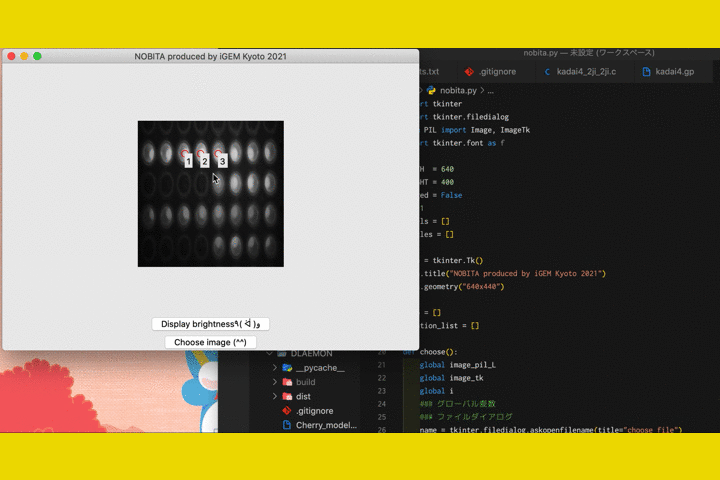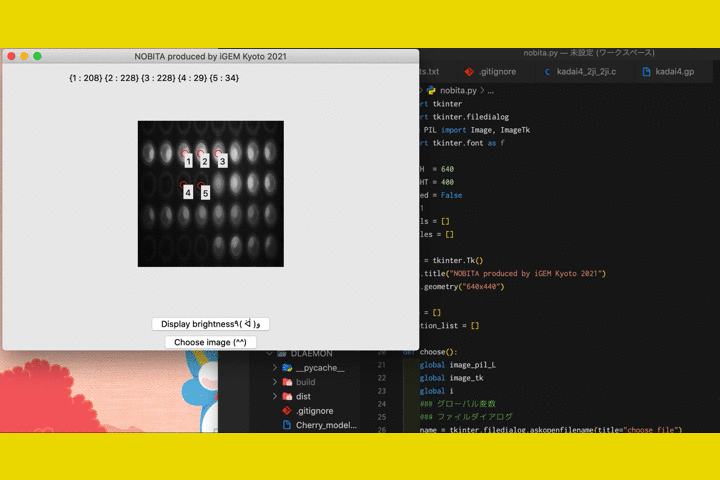
Step 5. Press the "Display brightness" button to display the result in the format {number : brightness}.

Future prospect
As for DLAEMON, All of the data used for the study and verification were carefully taken photo, and it is easy to tell whether a disease is present or not without using a software. However, there are many photos that are not clear and difficult to tell whether they are diseased or not. This would make it difficult to use this software in the field. In order to build an AI that can adapt to field data, we need a lot of data from the field.
Also, if we can detect and output only diseased leaves from a photo with multiple leaves, we can save the time of cutting and photographing each leaf. We would like to create such an AI. In order to do so, we need to collect a large number of photos of many leaves, including infected ones, in order to verify the accuracy of the AI.
NOBITA, if it could be equipped with a function to automatically determine where the sample is, it would reduce the time and effort and make it even easier to use. Also, if we can determine a specific threshold value for luminance to distinguish whether a sample is positive or negative, it will enable more accurate and rapid diagnosis. For this purpose, it is necessary to collect more data from experiments, perform machine learning, and conduct trial and error. In addition, by combining the positive/negative results obtained using NOBITA with leaf images, a new data set can be created, and DLAEMON can be evolved into AI software that can handle an even wider range of data.
If the above can be put into practice, it is expected that DLA, the detection system for leaves would become more accurate.
Also, if we can detect and output only diseased leaves from a photo with multiple leaves, we can save the time of cutting and photographing each leaf. We would like to create such an AI. In order to do so, we need to collect a large number of photos of many leaves, including infected ones, in order to verify the accuracy of the AI.
NOBITA, if it could be equipped with a function to automatically determine where the sample is, it would reduce the time and effort and make it even easier to use. Also, if we can determine a specific threshold value for luminance to distinguish whether a sample is positive or negative, it will enable more accurate and rapid diagnosis. For this purpose, it is necessary to collect more data from experiments, perform machine learning, and conduct trial and error. In addition, by combining the positive/negative results obtained using NOBITA with leaf images, a new data set can be created, and DLAEMON can be evolved into AI software that can handle an even wider range of data.
If the above can be put into practice, it is expected that DLA, the detection system for leaves would become more accurate.
And as the DLA system becomes more sophisticated, DLAEMON will be able to perform better and better, and will be able to identify diseases from photos of many leaves without having to examine each leaf individually. Then, it will be possible to mount DLAEMON on a drone and take photos of farmland from above to identify the location of diseased leaves. We hope that DLAEMON and NOBITA will make small "I wish I could do this" things come true.
Programs
References
- Thomas Bayes (1763) ”An Essay towards solving a Problem in the Doctrine of Chances” link
- (JAPANESE) 住友化学園芸 病害虫診断アプリ ガーデンドクターAI link
- (JAPANESE) 塩田 大河 , 鍵和田 聡 , 宇賀 博之 , 彌冨 仁 (2020)"茎部に発生する植物病害自動診断装置の提案" link
- kaggle.com PlantVillage Dataset link
- Train/Dev/Test sets - practical aspects of Deep Learning | Coursera
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Microsoft Research (2015) "Deep Residual Learning for Image Recognition" link
- Team: UiOslo Norway-iGEM 2018 link
- Team:USP-Brazil-iGEM 2017 link
- Yunhui Guo, Honghui Shi, Abhishek Kumar, Kristen Grauman, Tajana Rosing, Rogerio Feris (2019) "SpotTune: Transfer Learning through Adaptive Fine-tuning" link
- Filip Radenovic, Giorgos Tolias, Ondˇrej Chum (2018) "Fine-tuning CNN Image Retrieval with No Human Annotation" link